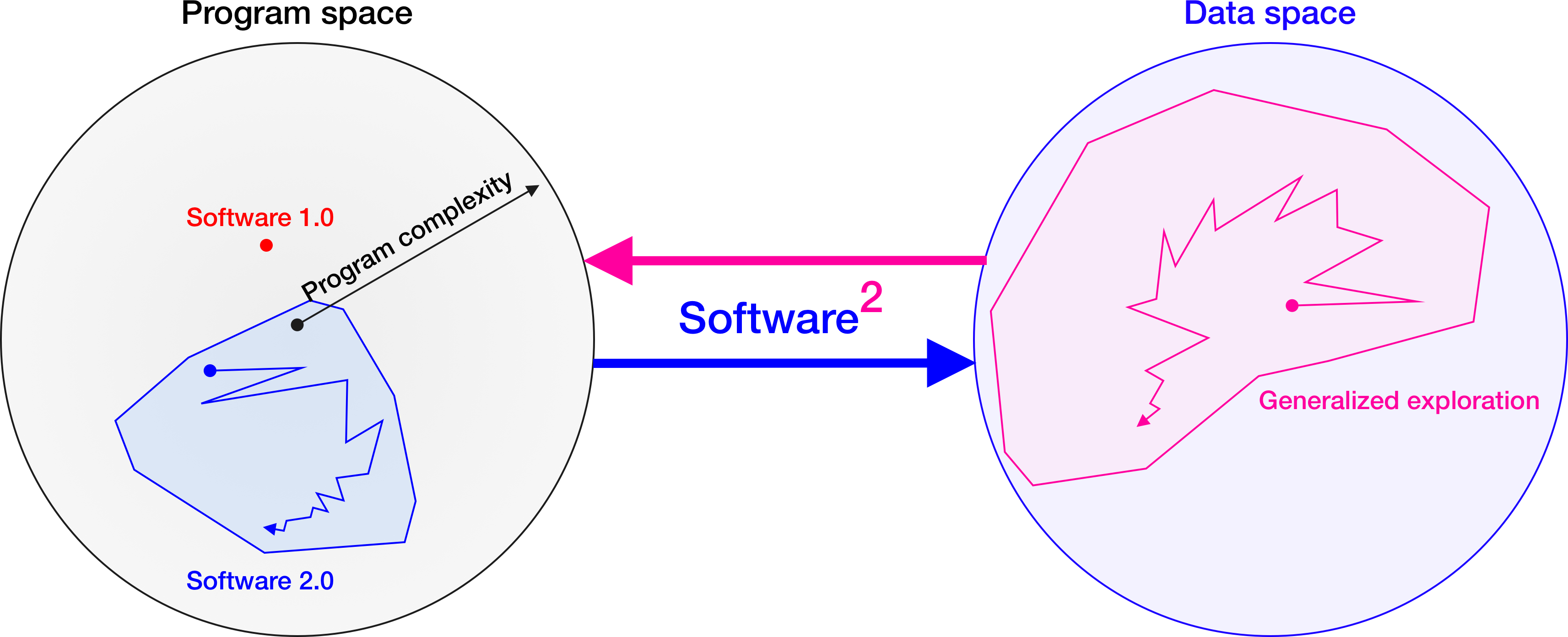
Software²
A new generation of AIs that become increasingly general by producing their own training data
We are currently at the cusp of transitioning from “learning from data” to “learning what data to learn from” as the central focus of AI research. State-of-the-art deep learning models, like GPT‑[X] and Stable Diffusion, have been described as data sponges,1 capable of modeling immense amounts of data.2 These large generative models, many based on the transformer architecture, can model massive datasets, learning to produce images, video, audio, code, and data in many other domains at a quality that begins to rival that of samples authored by human experts. Growing evidence suggests the generality of such large models is largely limited by the quality of the training data. Yet, mainstream training practices are not inherently data-seeking. Instead, they ignore the specific quality of information within the training data in favor of maximizing data quantity. This discrepancy hints at a likely, major shift in research focus in the coming years, toward innovating directly on data collection and generation as a principal way to improve model performance.
The problem of collecting informative data for a model is, in essence, exploration—a universal aspect of learning. In open-ended domains like the real world, where the set of possible tasks of interest is effectively unbounded, exploration is essential for collecting additional data most appropriate for learning new tasks and improving performance on those already learned. Such open-ended learning is perhaps the most important problem setting for machine learning (ML) systems, because the real world, where they are deployed, is exactly such an open-ended domain. Actively acquiring the right data to train on at the right time is a critical aspect of intelligence that allows learning to progress efficiently—in other words, it allows for “learning to walk before you run.” So why is the concept of exploration largely missing in the recent discourse around training more general models?
One reason for this oversight may be that exploration, as typically studied in reinforcement learning (RL) and supervised learning (SL)—where it appears as some variation of active learning—is primarily designed with a static, predefined dataset or simulator in mind. Just as research in SL primarily focuses on optimizing performance on static benchmarks like ImageNet, RL largely focuses on the setting of a static simulator of a task or game. This focus makes the existing notions of exploration unsuitable for learning in open-ended domains like the real world, where the set of relevant tasks is unbounded and cannot fit into a static, predefined data generator.
Our recent position paper talks about the idea of generalized exploration, which connects the concepts of exploration between SL and RL and extends their application to open-ended domains, where exploration serves as the critical data-gathering process for open-ended learning. Such open-ended exploration processes can be expected to serve as a key component in driving progress toward more generally-intelligent models. Over the next several years, considerable research investment will likely shift away from model design and optimization and instead, turn toward the design of exploration objectives and data-generation processes.
The high-level idea of an ML system that generates its own training tasks (and thus data) is of course not new. This idea has been described to various degrees by Schmidhuber as “artificial curiosity”, and by Clune as an “AI-generating AI.” Here, we seek to motivate the perspective on why now is a pivotal time for these ideas to gain traction in practical, real-world ML systems.
If deep learning can be described as “Software 2.0”—software that programs itself based on example inputs/output pairs, then this promising, data-centric paradigm, in which software effectively improves itself by searching for its own training data, can be described as a kind of “Software²”. This paradigm inherits the benefits of Software 2.0 while improving on its core, data-bound weaknesses: While deep learning (Software 2.0) requires the programmer to manually provide training data for each new task, Software² recasts data as software that models or searches the world to produce its own, potentially unlimited, training tasks and data.
| Software 1.0 | Software 2.0 | Software² | |
|---|---|---|---|
| Interface | Instructions | Task objective | Exploration objective |
| Domain | Task-specific | Task-specific | Open-ended |
| Adding new features | Manual | Manual | Automatic |
The rest of this article provides a quick tour of the motivations and principles behind Software². A more detailed discussion on these ideas can be found in our recent position piece, “General Intelligence Requires Rethinking Exploration.”
A general intelligence?
Deep learning reframes programming as optimization: Rather than coding a sequence of instructions to perform a particular task, simply define an objective function measuring success at that task and use it to optimize a deep neural network (DNN) to do the task for you. This perspective was clearly laid out in Andrej Karpathy’s essay “Software 2.0” in 2017. A major benefit of this approach is that directly searching over the space of programs that can be encoded in the weights of a large DNN can result in finding solutions more complex than what a human programmer can manually code up. Just imagine the difficulty of writing a program by hand to caption an image or the opposite, to go from any text description to a matching image.
It may be an understatement to say that since the publication of “Software 2.0,” deep learning has advanced greatly. Most remarkably, we have since found that trained DNNs do not only excel at the specific tasks on which they were trained, but can often become more generally capable, learning to succeed at tasks beyond those it saw during training.
The high-fidelity generation of data formats like text and video—which can encode detailed descriptions of nearly any task of interest—illustrates how a DNN can become proficient in a wide range of tasks despite training on a single task objective: Learning to predict the next token in samples from an Internet-scale text corpus necessarily requires the model to learn the structure of many kinds of text content, which will naturally include categories of text corresponding to different tasks like translation, answering questions, summarizing, writing code, or even explaining jokes. Recent work takes this idea further, by representing a variety of tasks—including language modeling, multi-modal question answering, and controlling simulated and embodied agents—as a sequence modeling problem. By training a single large model to generate such sequences piece by piece, the resulting model can learn to perform these tasks by simply autocompleting the rest of the sequence from some initial starting segment that sets the scene for the task of interest (often referred to as a context or prompt).
A natural question is then to ask if such deep learning approaches can produce a generally-intelligent model—for example, one capable of at least performing any task its human beneficiaries might want to perform themselves. Answering this question is challenging, partly because most definitions of “general intelligence” are vague or unquantifiable in degree. To get a better handle on this question, we choose to instead consider general intelligence in relative terms: Model A is more general than model B in domain D if A is capable of exceeding B on at least one task in D, while matching B in all others—that is, if A’s performance strictly dominates that of B’s across all tasks in D. From this perspective, general intelligence is not a fixed property, but one that can continually change over time for a given task domain, relative to other intelligences. We then use the term increasingly general intelligence (IGI) to refer to a system exhibiting continual improvement in its relative general intelligence with respect to other non-learning agents, including previous versions of itself. This definition of course assumes the task domain is rich enough to support this kind of continual improvement. In this sense, we say an IGI perform open-ended learning, and call its associated process for collecting training data open-ended exploration. This view of general intelligence makes clear that a system that does not perform continual, open-ended exploration cannot, by definition, be an IGI.
Open-Ended Exploration
Without the ability to continually seek out new, informative training data, learning will plateau. Exploration methods in RL and SL directly prioritize the collection of such data, based on proxies for the learning potential of the data, often estimated as some measure of novelty with respect to past training datapoints, the model’s epistemic uncertainty, or how much the model’s predictions change after training on that data. However, exploration methods in RL and SL largely focus on collecting informative samples in a single, static, predefined simulator or dataset. Static data sources are poor reflections of the infinite and ever-changing nature of the real world. Exploring beyond the confines of such static data generators requires rethinking exploration. The framework of generalized exploration shows the path forward.
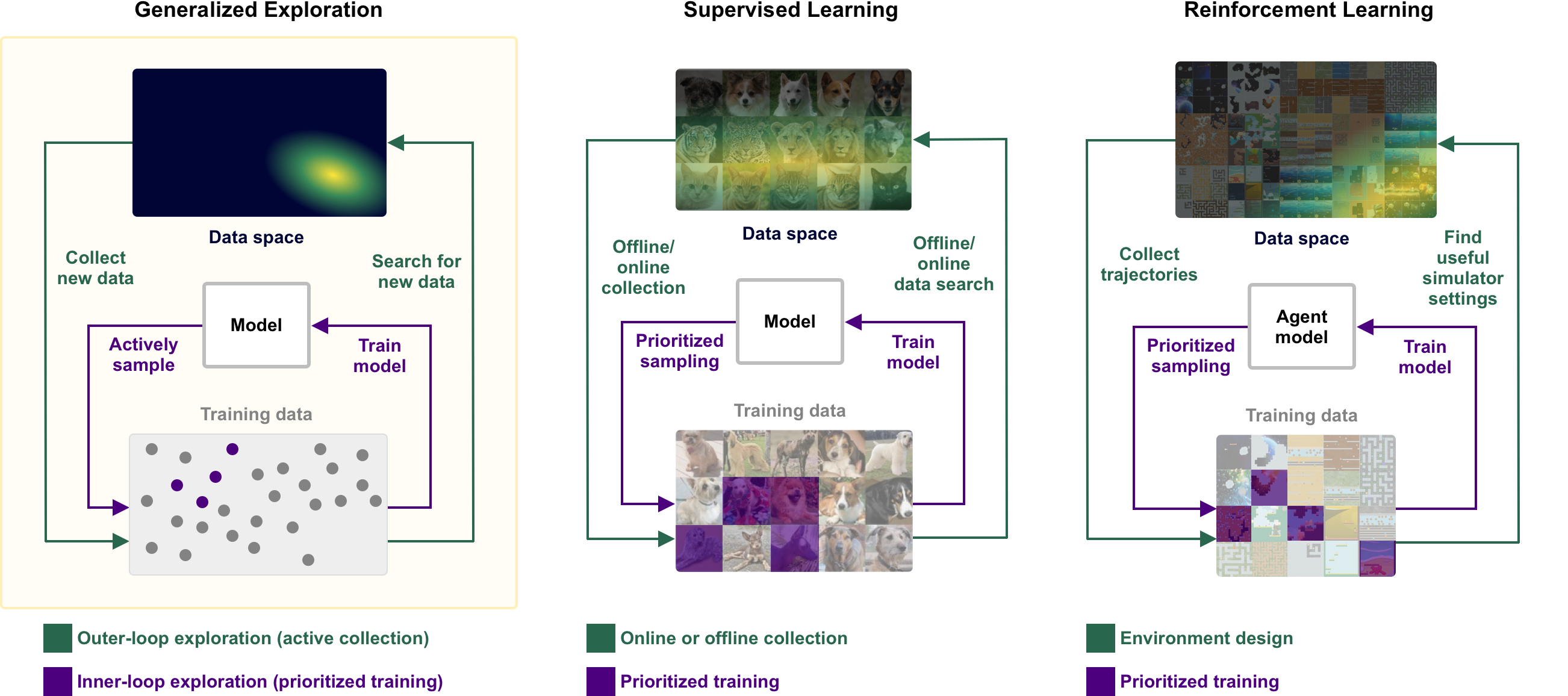
Unlike existing notions of exploration in RL and SL (where it takes the form of active learning), generalized exploration seeks the most informative samples from the full data space. In general, the full data space can be unbounded and cannot be captured by a single, predefined dataset or simulator. In these cases, we have to continually collect more data from outside of the dataset or simulator to gradually expand the scope of the dataset or simulator, a kind of bootstrap process. For example, a typical RL agent can experience transitions for a particular game in a procedurally-generated environment, but it is unable to explore the full space of possible transitions across all possible games. Generalized exploration would instead explore the space of transitions possible across all games, rather than just those from a finite number of games. When the data space being explored is unbounded, this process performs open-ended exploration by coupling data collection to the agent model, progressively searching over transitions on which the current agent model experiences the most learning progress.
How can we explore the full data space? We need a way to parameterize the search space over all possibly useful data and search criteria to guide exploration in this space. A natural search space is that of all mutually-consistent data-generating programs. Exploration can then search this space for programs that produce data with the highest learning potential for the current model. These programs should be mutually consistent in the sense that the input-output pairs they produce should not contradict each other. Such programs might correspond to a static dataset, a data distribution, or a simulator for a category of tasks. However, learning potential will likely be insufficient as the sole exploration criterion. Also important is data diversity, as there may be many parts of the data space that offer high learning potential. Moreover, there are likely large regions of the data space that are irrelevant to any real tasks of interest, so it may be important to constrain the exploration to be close to the kinds of tasks we care about.
Of course, we still need some way to actually search through the space of all data-generating programs. In practice, we as the system designers, can manually define the high-level spec of programs of interest, such that they are grounded to the invariant features of reality that we care about, but broad enough to encompass a rich, open-ended space of tasks. Such programs might incorporate hooks into the real world via an API or human intervention, allowing them to output both real and synthetic data. A related approach might be to search the latent space of a generative model of the data space to produce new data that maximizes the learning potential of the model. Should learning begin to plateau, we can intervene by evolving the spec, perhaps with the assistance of a model-in-the-loop that updates the spec in directions predicted to provide data with greater learning potential. In a sense, the research community’s continual, collective invention of new benchmarks plays the role of such a continual search over data-generating programs. Recent works like BIGBench, a benchmark composed of a growing set of human-specified benchmarks, directly reflects this pattern. Similarly, Dynabench uses humans-in-the-loop to continually generate new, challenging data for the current model.
Data as Software
By equating data with a kind of generative software, Software² echoes the Von Neumann computer architecture, in which program instructions and data were both stored equivalently in memory. In the Von Neumann architecture, software at rest is equivalent to data. In Software², data at play is equivalent to software. The ability of Software² programs to continually self-improve makes them an important component to realizing systems demonstrating IGI. In the coming years, there will likely be much investment in developing different kinds of Software² systems. Much research focus can be expected to shift from designing and optimizing models to designing and optimizing processes that generate training data for such models. Key components of the Software² stack are actively being developed across many areas of ML research:
Automatic curriculum learning: In both SL and RL, automatic curriculum learning methods directly search for datapoints or simulator configurations that maximize an agent’s learning potential. Such methods, including recent methods for environment design, can be used to perform generalized exploration, given an appropriate parameterization of the data space, like a rich simulator, world model, or a generative model of programs corresponding to possible tasks.
Generative models: Transformer and diffusion models, like the DreamFusion model that generated the synthetic 3D data above, have revolutionized our ability to model complex, Internet-scale data distributions. Such generative models can serve as world models, continually updated with real world data, and sampled as an open-ended data generator. A special case of this pattern is the particularly striking, recent finding that large language models can self-improve by training on their own generated outputs, when filtered against some measure of data quality.
Human-in-the-loop interfaces: Human guidance will likely play a crucial role in ensuring Software² systems remain grounded to the kinds of tasks we want our IGIs to perform. Works like InstructGPT, Dynabench, Aesthetic Bot, and GriddlyJS provide promising approaches for incorporating human preference and expertise into the training loop.
Summoning an IGI
What might a real world implementation of Software² look like? A simple example would be to imagine a virtual assistant that can fully access the web by controlling a browser, including accessing chat interfaces to communicate with people. Most tasks of interest to humans, from scheduling meetings to ordering groceries, can already be performed through a web-based intermediary—think a web app or on-demand service. The set of such tasks on the web, of course, is continually growing larger, as people continue build new websites and invent new kinds of activities. This virtual assistant can then, in principle, become an IGI, learning to perform an increasingly general set of tasks via the web.
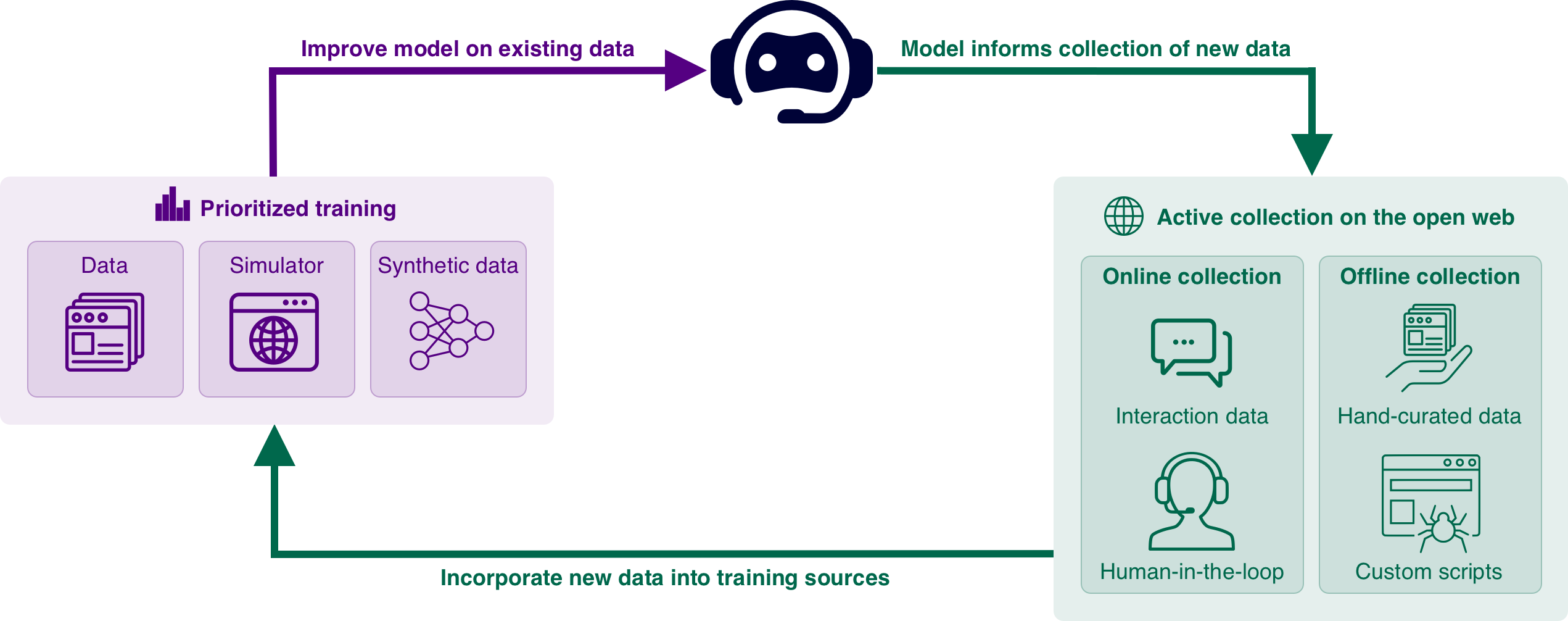
We can apply the principles of Software² to train this virtual assistant, through generalized exploration over the space of data-generating programs grounded to the web domain—in this case, specific websites. Much of this training can occur inside a procedurally-generated simulator or world model of web pages that is continually updated through a combination of the virtual assistant’s own experiences on the real web and specific web pages that we, the system designer, deem particularly important for training. Moreover, exploration might actively search for data in the form of demonstrations from websites like YouTube, used to both improve its own decision-making and inform the simulator or world model used to generate synthetic data for training. As usual, the virtual assistant can also directly train on its own experiences navigating the real web. Over time, we can expect such a learning system to produce an ever more capable virtual assistant and the exploration process to gradually encompass wider reaches of the space of websites as it continually seeks websites from which the virtual assistant can learn new things. At a high level, we can expect Software² systems to resemble a large-scale search engine, providing an interface into a powerful model whose core components are continually updated with the assistance of a data-crawling process constantly scouring both the Internet and real world for new and useful information.
As our learning algorithms become ever more powerful, we stand to gain immensely from thinking deeply about what data to feed these algorithms. We are optimistic that, given the relentless growth of the open web and the rapidly maturing components of the Software² stack, we will soon see the realization of widely useful IGIs much like the one just described.
This brief article painted the broad strokes of Software², a quickly emerging, data-centric paradigm for developing self-improving programs based on modern deep learning. It is an approach that is likely to be as influential to the design of future software systems as the recent, ongoing transition to Software 2.0. Still, we have only scratched the surface. If these ideas pique your interest, you might enjoy reading the extended discussion in our full position paper.
Thanks to Edward Grefenstette, Tim Rocktäschel, and Peter Zakin for their insightful comments on drafts of this post. Further, many thanks to Michael Dennis, Gary Marcus, Shane Legg, Yoshua Bengio, Jürgen Schmidhuber, Robert Kirk, Laura Ruis, Akbir Khan, and Jakob Foerster for useful feedback on our position paper, “General Intelligence Requires Rethinking Exploration.”
For attribution in academic contexts, cite this work as
@article{jiang2022rethinking,
title={General Intelligence Requires Rethinking Exploration},
author={Jiang, Minqi and Rocktäschel, Tim and Grefenstette, Edward},
journal={arXiv preprint arXiv:2211:07819},
year={2022}
}
-
To our knowledge, the term “data sponge” was first coined in Eric Jang’s excellent article, “Just Ask for Generalization.” https://evjang.com/2021/10/23/generalization.html. ↩
-
The recent Stable Diffusion model effectively compresses approximately 100GB of training data into a mere 2GB of model weights. ↩